
Join Us on Apr 30: Unveiling Parasoft C/C++test CT for Continuous Testing & Compliance Excellence | Register Now
Jump to Section
Adding Life to Service Virtualization: Stateful & State Transition Testing
August 3, 2023
8 min read
Creating a stable virtual representation to achieve a stateful behavior of your development workloads can be tricky. Here is how Parasoft Virtualize can help you simulate and test your virtual services.
Jump to Section
Jump to Section
In service virtualization, a critical part of creating realistic virtual services is ensuring that the service has stateful behavior so it can retain its state from test run to test run. But what is the limit? When does simulation become too much simulation? Let’s dive into state transition testing and how to know when you need it.
To accelerate functional testing, it’s essential to have unrestrained access to a trustworthy and realistic test environment. A complete test environment includes the application under test (AUT) and all of its dependent components, such as APIs, third-party services, databases, applications, and other endpoints.
Service virtualization enables teams to do the following, which ultimately enables teams to test earlier, faster, and more completely.
- Get access to that complete test environment they need, including all the critical dependent system components.
- Alter the behavior of those dependent components in ways that would be impossible with a staged test environment.
Stateful Behavior
A critical part of creating realistic virtualized dependencies is having stateful behavior. In other words, a virtualized dependency can retain its state from test run to test run. Consider an example of simulating a virtualized shopping cart component. A simple API allows for searching, adding, retrieving, and deleting items from the cart.
With stateless behavior, simulating searching and saving items to the cart won’t change the state of the cart. Testing the sequence of retrieving and deleting data from the cart will fail because the cart will remain in its initial state (empty), as illustrated below.
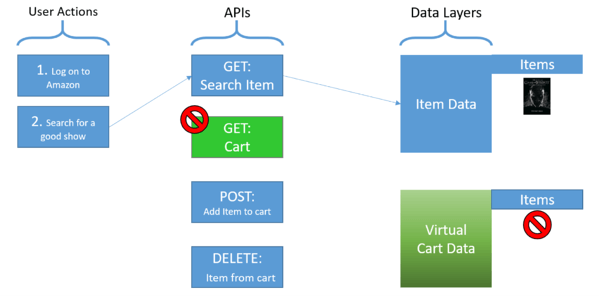
However, if the virtual shopping cart is given stateful behavior, where its state (empty or with one of more items in it) is retained from test to test and also changes based on the inputs from the application under test, you can start to test the process meaningfully.
Using stateful testing, the virtualized service can now change state from empty to “filled with item added,” and return the appropriate information. If an item is added to the cart and the AUT queries the cart, the appropriate data is returned. A more realistic test is possible using stateful testing, and querying the cart now returns the item added, as shown below.
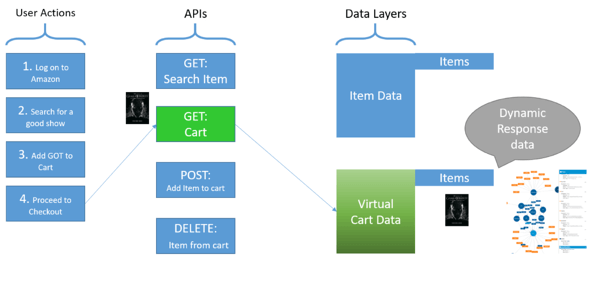
To summarize, to have trustworthy and reusable virtual services, it’s critical that they can mimic the real service sufficiently to provide meaningful output back to the application under test, and this can require stateful testing.
In addition to statefulness of the virtual service itself, you may also need to simulate changes in state based on different potential inputs, and this is called state transition testing.
What Is State Transition Testing?
State transitions are the action component of finite state machines, which are defined as:
“…an abstract machine that can be in exactly one of a finite number of states at any given time. The FSM can change from one state to another in response to some external inputs; the change from one state to another is called a transition. An FSM is defined by a list of its states, its initial state, and the conditions for each transition.”
State machines are a useful way to describe objects and are often explicitly used as a programming model. In other test cases, like our shopping cart, there might be an implicit state machine to describe its behavior. Consider the following state machine for the shopping cart example above.
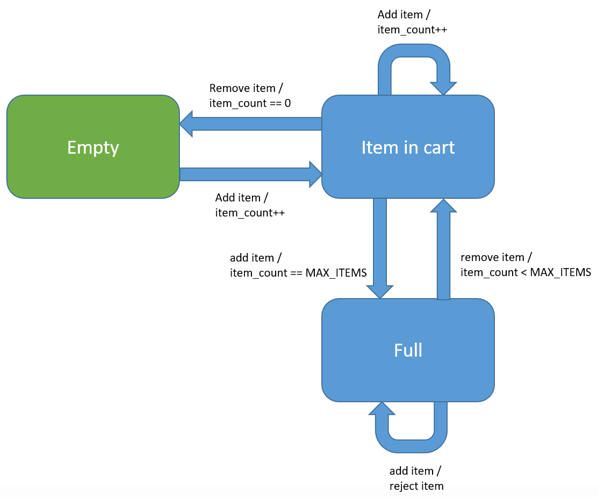
The initial state of the cart is empty. As items are added to the cart, the state transitions from “Empty” to “Item in cart.” Transitions are initiated in response to events. In this case, adding or removing an item from the cart.
Transitions often have conditions before they are taken, for example, transitioning back to the Empty state only occurs when the number of items is zero again. Transitions often perform actions, such as incrementing the count of items in the cart, in this example. Although it’s unlikely that the cart is programmed as a state machine, there is an implicit one that is useful for defining its behavior.
Consider another simple example of a user login component that locks a user out after a certain amount of retries:
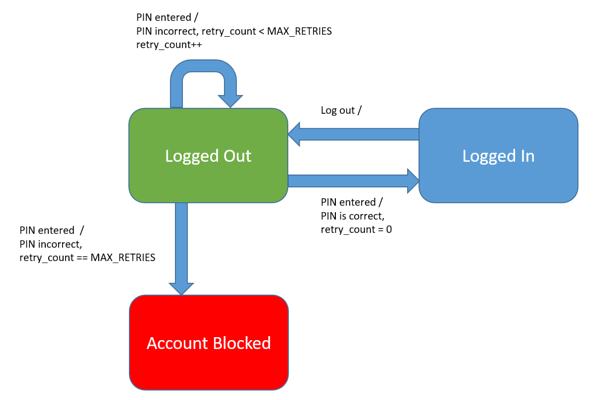
In the login component, the initial state is logged out. A user can only be logged in when a correct PIN is entered. After a defined number of login attempts (MAX_RETRIES) the account is blocked. In this test case, Account Blocked can be considered a final state since there is no way to transition from it.
State Transition Diagrams
As shown in the two above transition examples, state diagrams are graphical representations of finite state machines. They model the behavior of a system or process that can exist in different states and the transitions between those states based on certain events or conditions.
In a state diagram, states are represented as rounded boxes and transitions between states are arrows. Each state represents a particular condition or mode of the system. Transitions indicate how the system can move from one state to another and are usually labeled with the event that causes the transition.
Events in state machines can be external inputs, internal actions, or the passage of time. When an event occurs, the system undergoes a transition and moves to a new state.
State Transition Tables
State transition tables are tabular representations used to describe the behavior of a state machine in a systematic way. The table defines the possible states, input events, and resulting state transitions.
In a state transition table, rows represent states and columns represent an input event or condition. The cells of the table specify the resulting state when a particular event occurs in a specific state. This allows for a concise and structured representation of the state transitions.
| State / Event | PIN Entered (check PIN, PIN correct) | PIN Entered (PIN, PIN incorrect, increment retries, retries>=MAX) | PIN Entered (check PIN, PIN incorrect, increment retries, retries Logout | |
|---|---|---|---|---|
| Logged Out | Logged In | Account Blocked | Logged Out | |
| Logged In | Logged Out | |||
| Account Blocked |
Advantages and Disadvantages of State Transition Testing
The advantages of using state transition testing include the following.
- Provides thorough test coverage by systematically examining all possible states and transitions in the API, which ensures more complete coverage of the behavior of the API.
- Through the increased coverage comes better bug and security vulnerability detection.
- Becomes a more succinct way to express behavior as testers become more familiar with it and simplifies API testing overall.
- Reusable tests reduce the work required for regression testing.
There are some disadvantages to state transition testing. First and foremost is the level of effort required to represent a complex API. If the translation of the API behavior outputs in a complex state machine, it will be hard to understand, use, and maintain. Plus, state transition testing is sensitive to changes in the API—it requires constant maintenance to keep up with these updates.
When to Use State Transition Testing?
State transition testing makes the most sense, unsurprisingly, when the API has a stateful nature, such as maintaining a session or context across multiple requests. This type of testing helps verify that the API correctly manages and maintains the state throughout the interaction, ensuring consistent behavior across different requests and transitions.
APIs may document their behavior in terms of states and events, in which case verification can take the same form. In other cases, the API may involve a complex business process that has multiple stages in the workflow. State transition testing can be used to better test these complex scenarios.
Simulating State With Parasoft Virtualize
So, how does this help with testing and virtual services? Well, it’s possible to use Parasoft Virtualize to simulate stateful behavior so that services return appropriate responses from test run to test run, representing realistic values expected by the AUT.
Virtualized services react to input from testing and persist values as needed, extending the usefulness of captured and simulated test data, which remain static unless enhanced with stateful behavior. In Parasoft Virtualize, a service is virtualized as CRUD (Create, Read, Update, Delete) to indicate that its test data source is persistent and can be manipulated as needed during testing. See the screenshot below.
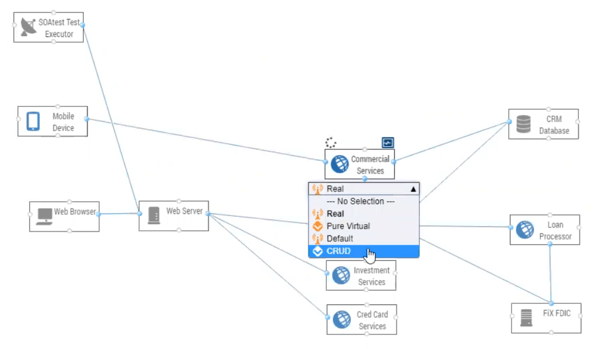
Parasoft Virtualize supports stateful behavior in the test data source or engine associated with each virtual service, which not only stores test data, but also provides the CRUD tool to manipulate data based on reacting to received API requests. These updates to data in the test date source are based on input events, like those discussed above in the state transition diagrams—input event arrives, state transition occurs, and action takes place.
To support all of this, the test data management tool in Parasoft Virtualize is configured to perform an update based on a data source and arriving event.
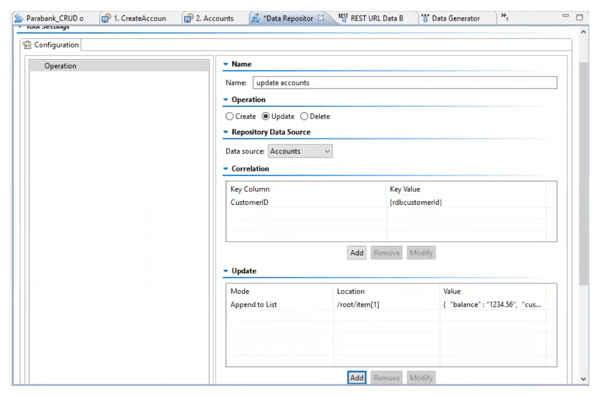
The updates to the test data source can be individual data items or entire objects. The tool also allows you to create and delete records depending on the business rules required. In fact, it’s powerful enough to simulate complex behavior, which begs the question, when is too much simulation, too much?
The Pros & Cons of Stateful Virtualization
Using pure virtualization is helpful in testing since it removes the complexity of dealing with a real service and isolates the application under test. In addition, removing live services means tests can be run in parallel, on multiple desktops at the same time, without impacting production systems or the need for a dedicated copy of the service. But a pure virtual server only returns acknowledgment as in “yes, this API was called.” In many cases, this is sufficient, until, of course, it isn’t. As more complex test cases emerge, we need our virtualized servers to smarten up.
Using the shopping cart example from above, it’s much more useful for your virtual shopping service to not only acknowledge that items have been added to the cart but actually simulate adding items to the cart. This way, a query to determine the number of items in the cart will succeed with a correct value. We could also simulate a “cart full” state as described in the state machine representation above. Stateful behavior is necessary to give our tests more meaningful results and increase coverage of test cases.
But there comes a point when simulating business logic becomes too complex. The intent of virtualization is to decrease work and increase productivity, so there are diminishing returns in simulating complexity.
The cutoff is hard to say, but if complexity is going well beyond our shopping cart or login example, then it becomes hard to justify the effort. How can you be sure that you’re simulating the correct behavior? You don’t want a situation where your application is built to work with a simulated service but doesn’t work correctly with the real thing! The use of live services is still needed in validation. Luckily, Parasoft CTP’s Environment Manager module makes switching easy.
Summary
Stateful behavior is a critical part of creating realistic virtualized services, needed to help isolate applications under test. Retaining the test data state from test to test is necessary for more realistic and useful tests. Parasoft Virtualize provides a comprehensive test data management solution that gives life to virtualized services with stateful and state-based responses to inputs from API calls.
Simulation should be used cautiously, as simulating complex business logic has diminishing returns and the risk of straying too far from the real thing. A smart use of simulation pays great benefits in isolation, which in turn decouples the dependencies on live servers. However, since live servers still play a role in final validation, service virtualization tools like Parasoft Virtualize are required to support the mixing and matching of these environments seamlessly.
How to Choose the Right Service Virtualization Tool
Recommended Content

Whitepaper


