Discover TÜV-certified GoogleTest with Agentic AI for C/C++ testing!
Get the Details »
Jump to Section
Parasoft Blog


If you're looking for a Selenium cheat sheet to get you going with Selenium web testing, here's an experience-packed breakdown of how to get started with Selenium.
Jump to Section
During my Selenium learning experience, I discovered some tips and tricks to get started. Here are some great resources that could help you, too.
I learned how to use Selenium because of Parasoft’s product for Selenium testers, Parasoft Selenic. I had some experience with web testing, writing Java code, and JUnit, but I had never used Selenium before. This post shares some resources I found helpful in ramping up. First, some background on Selenium.
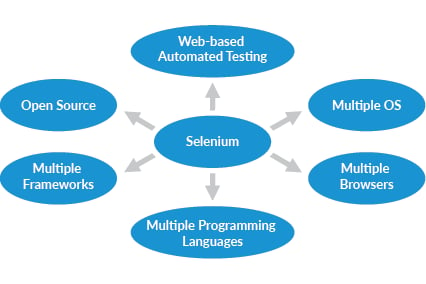
Selenium is an open source testing framework specifically designed to validate web applications across various platforms and browsers. It’s an automation testing tool that’s distinctly different from others thanks to supporting multiple operating systems, browsers, programming languages, and frameworks.
The first thing to do when learning Selenium is to make sure you understand the difference between Selenium IDE and Selenium WebDriver. I thought that Selenium IDE, a GUI record/playback program built on top of Selenium WebDriver, would be a great way to get started. I quickly found myself running into limitations where playback was unsuccessful with bad/missing locators and realized that any serious Selenium tester is writing code using the Selenium WebDriver. The die was cast. I had to start writing code.
Test automation, on the whole, provides a host of benefits from increased code coverage to reduced time to market. Selenium’s popularity is likely related to the enthusiastic community surrounding it. It’s relatively easy for beginners to learn.
In automation testing, Selenium expedites the testing process, improves accuracy, and allows testing under scenarios that would be laborious if done manually. Selenium gives developers the flexibility to design custom automation frameworks and it supports parallel test execution to boost testing speed and efficiency.
The Selenium WebDriver libraries are available for several different languages, making Selenium accessible to a wide audience of people. Since I’m most comfortable writing code in Java, I stuck with that. (Also, while JUnit is not required for Selenium testing in Java, I don’t see why anyone wouldn’t use it, as it comes with a bunch of features specifically geared for writing test cases in Java.)
Lastly, if I was going to be writing JUnits, then I figured I might as well be writing them in an IDE. There are two IDEs that are mostly used in the industry for Java: Eclipse, and IntelliJ. Most of my career has been with using Eclipse, so I stuck with that.
Having made these decisions, I was ready to get started.
Before you get going, make sure you have some prerequisite skills, to get going with test automation basics.
Familiarity with HTML and CSS. You shouldn’t be afraid of a website’s page source, and you should understand how the page source translates to what you see rendered in the browser. If HTML is totally foreign to you, then I suggest some foundational education. Here is a great website that helped me in my early education on the web:
Browser’s Developer Tools & XPath. Another foundational skill is understanding how to locate elements on a page. Selenium WebDriver supports several mechanisms for doing this, which you’ll soon get exposed to. You’ll want to be comfortable using the browser’s developer tools to locate elements on a page, and here’s a great tutorial to bring you up to speed with Chrome:
If you’re looking to transition into a test automation engineering role, then you’ll need to develop some coding skills. Before you freak out, the good news is that writing code to automate web testing in Selenium is relatively easy. In fact, I think Selenium is a great way to learn coding; the code you’ll be writing is narrowly constrained so you’re less likely to get totally overwhelmed. It shouldn’t be hard finding free tutorials and lessons to get you started with whatever language you choose. For the purposes of learning what you need to know for Selenium, I found a fantastic tutorial that covers Java and Selenium for a total beginner:
If you do choose Java, then I recommend also learning JUnit, which is a popular testing framework for Java. Here’s a great tutorial that covers JUnit AND the final lesson covers applying JUnit with Selenium testing:
Besides the Tutorial from toolsqa, another resource I found myself frequenting was this:
These two resources will cover all the topics necessary for you to set up your environment with Eclipse, Java, JUnit 4, Selenium WebDriver, and Maven.
…Maven? What’s that? One comment I’ll make is that most tutorials I found put Maven as an advanced topic further down the list. Maven is a build tool that makes compiling, testing, and deploying code easier to manage with all their required dependencies. Like JUnit, Maven is another optional item, but I want to bring it up now because it makes your project setup easier once you know what to do. If you start with Maven, then you won’t have to think about converting your Java Project to a Maven Project later, just start with Maven from the beginning! The tutorial I liked best for this was from:
Both of the tutorial references I mentioned do a good job walking you through creating your first script. The toolsqa article assumes less coding knowledge and the softwaretestinghelp.com link covers more ground, but they’re both excellent:
Once you’ve gotten your first script up and running, and you’re up to speed with JUnit, the final lesson from toolsqa’s JUnit tutorial will help you refactor your initial scripts to the JUnit format:
After you’ve gotten comfortable with Selenium basics and you have a script that plays back a scenario or two in your browser, you should be ready to go to the next level. The Page Object Model is a way of organizing your Selenium test code to make it more maintainable and decrease duplicate code.
My tests up until this point had all the test code contained within my test method. So, I went through a 2-step process, first refactoring my existing test to Page Object Model, and then second refactoring again to optimize it with the Page Factory pattern. This was an instructive 2-step process, and I can only imagine how much I’d be regretting it if I skipped these best practices and ran wild creating test after test. You can do this automatically if you are using the Smart Recorder in the Parasoft Selenic Free Edition.
Here are a couple of guides that I used to educate myself on the topic:
If this seems like extra work and extra code for the same result, you’d be right. And if you’re only ever going to have 1 or 2 tests, then maybe this is overkill but that’s never the case for a test automation engineer. This pattern ends up making all the sense in the world when you’re building a robust regression test suite of 100s or 1000s of tests. Code re-use is going to save you unbelievable amounts of time in the long run.
As you start experimenting with your Selenium scripts, you’ll start to appreciate why I listed locating elements on a page as a necessary skill. You’re going to find yourself in the browser’s developer tools extension A LOT, and you’re going to start experimenting with XPath. While there are many ways of locating elements on a page with Selenium, XPath is one of the most flexible and powerful. If you can’t uniquely identify an element with simple strategies like using an id, name, or link, then you’re looking at XPath or CSS Locators. Any reasonably complex Selenium test is going to need a little XPath here or there to locate stubborn page elements and the better you get with XPath the more effective of a tester you will become.
Alright Wilhelm, XPath is great, can you give me something more than homework here? Actually, yes! There’s also a nifty Chrome Extension (it’s also available for Firefox) called TruePath. This plugin does a decent job of coming up with lists of recommended XPaths to choose from that you can copy/paste into your Selenium locator code. It’s not always perfect, but I found it helpful in either presenting a Relative XPath I immediately liked, or presenting a Relative XPath that was close enough to something I liked, and I could then use that as my starting point to tweak.
Once locating elements becomes second nature, you’ll most likely run into another common problem. The web application you’re testing has AJAX (Asynchronous JavaScript And XML) calls that the browser is making to the server. Your Selenium script is blowing through the actions not giving the browser enough time to finish processing this asynchronous traffic. The e-commerce website I was testing had this problem where my Selenium test was clicking "Add To Cart" and then "View Cart" so fast that when it got to the Cart page, the cart was empty! I needed to tell my Selenium test to wait an appropriate amount of time before clicking "View Cart," but how to do that?
There are some basic Selenium lessons associated with wait conditions that the tutorials cover, but none of them seemed appropriate for something asynchronous and dynamic like this. How can I predict how long the web server is going to take to respond? Do I overestimate to be safe and make my test slower than it needs to be? Is there a better way? It turns out there is. Many modern web frameworks today are using the jQuery library in support of the AJAX calls they make to the backend server. Selenium WebDriver allows me to execute JavaScript as a test step, and I can execute some JavaScript that checks the status of jQuery to get a hint of when the browser is done talking to the web server and it’s OK to proceed. Buried deep in the toolsqa website, interestingly NOT part of the Selenium Tutorial, I found this:
For beginners, this extra information is great, but if you want something that’s more to the point, here’s a concise article on the same topic:
The last topic I’ll leave with you is one that plagues every Selenium tester, which is managing change. One of the drawbacks to web test automation is the frequency with which the UI changes and how that can impact the stability of your automated tests. As a test automation engineer, you’ll soon get uncomfortably used to the process of troubleshooting why a test failed to execute all the way through and whether that was:
Expect a lot of false alarms with your automated tests failing not because they found a bug, but rather because they need to be maintained or because the environment had an issue.
One of the strategies to help minimize this pervasive problem I’ve already touched on with Element Location. Often when a test fails to locate an Element, it’s because it is using a location strategy that is no longer valid on the newest deployment of the application. How you are locating an Element can matter here, so let’s discuss an example of how to write a locator that is resilient to change:
If you think about an absolute XPath to an Element like this:
/html/body/div[25]/div[2]/div/span/section[2]/div/h2/p
Boy, any little change to the HTML is going to break that thing. If you construct a Relative XPath like this:
//p[@id=’8232:0′][contains(.,’Guidance for Success’)]
Then your test stands a better chance of succeeding. Note the words "better chance." Sometimes the application will change so much that you’re simply out of luck. But writing more resilient tests will reduce the chance of future work for yourself. (Or you can check out the Parasoft Selenic.)
This same issue is also present with waiting. Many factors can cause instability in your test automation because of wait conditions. Using strategies like Smart Waiting on AJAX Using jQuery will help you reduce the likelihood of needing to address a problem with your test because of wait conditions. While on the subject, here’s a helpful tutorial about waits in Selenium:
Just like with element location, though, sometimes you’re going to be S-O-L and maintenance is unavoidable.
As you progress in your Selenium automation journey, it’s essential to explore tools that can enhance your testing capabilities and streamline workflows. Parasoft Selenic emerges as a valuable companion for Selenium tests, offering advanced features that can significantly level up your Selenium experience.
Parasoft Selenic’s Smart Recorder stands out for simplifying web UI testing, empowering both beginners and experienced testers to create Selenium scripts without extensive coding through its user-friendly interface. Efficient script organization is crucial for maintainability and reducing duplication, and Selenic champions this by leveraging the Page Object Model (POM). POM structures your tests for clarity and manageability, while the Page Factory pattern unlocks refactoring and optimization, ensuring your tests stay future-proof and adaptable.
Parasoft Selenic applies AI heuristics to determine if failures are due to a real regression in the application. Run your Selenium tests in sequence or in parallel with confidence, knowing that Parasoft Selenic’s self-healing capability with enhanced locator and wait condition strategies will detect unstable tests, modify them on the fly during execution, and show you how it kept them running.
Instead of having to execute thousands of tests before you know the quality of the build, Selenic optimizes your Selenium test suite to execute only the tests required to validate the code changes between the builds. Within its intelligent test selection capabilities, Selenic uses test impact analysis to reduce the time it takes to execute your tests, so you can get quicker feedback from the CI/CD pipeline.
Parasoft Selenic facilitates seamless project setup by integrating with Maven, a powerful build tool. Maven streamlines the compilation, testing, and deployment of your code along with its dependencies. Starting your Selenium project with Maven from the beginning can enhance project management and simplify future tasks, ensuring a smooth development and testing experience.
Whether you’re focused on test creation, handling asynchronous actions, or ensuring stability amongst changes, Parasoft Selenic provides a robust set of capabilities to elevate your Selenium automation to new heights.
The experience of learning Selenium has given me an appreciation for the challenges you can expect to face out there in your journey to become a test automation engineer. Any newbies feeling intimidated, just remember that this is easier than you think, and you’ll be an expert automated web tester in no time.
Try the Selenic Free Edition today if you’re ready to jumpstart your journey.
Optimize Selenium web UI testing with AI and ML.