Discover TÜV-certified GoogleTest with Agentic AI for C/C++ testing!
Get the Details »
Jump to Section
Parasoft Blog


There are many ways and techniques for detecting vulnerabilities in your software. One of the best ways is static analysis security testing (SAST). Here is how you can go about deploying SAST in software security testing.
Jump to Section
There are several techniques to identify vulnerabilities in software and systems. Smart organizations keep them in their "security toolbox" and use a combination of testing tools including:
The motivation to improve security through automated tools is to shift left in the software development life cycle (SDLC) the identification and remediation of vulnerabilities as early as possible. Fixes and remediation get more complicated as the application nears release. Figure 1 shows how the cost of remediating vulnerabilities increases dramatically as the SDLC progresses.
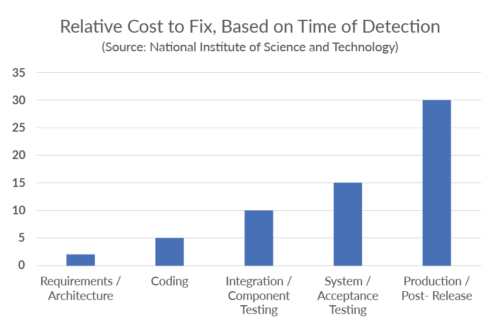
The increase in cost to fix vulnerabilities as the SDLC progresses.
For in-depth coverage of the economics of software security, check out The Business Value of Secure Software whitepaper. This post focuses on using static analysis security testing as part of an organization’s security practice.
As the name suggests, static testing means it’s applied statically. In other words, the analysis is performed on source code, binaries, and/or configuration files. Static tools use their understanding of the semantics of the source to deduce errors and vulnerabilities.
These "error detectors" are known as checkers or rules. If a rule is violated, a warning is issued with information on where in the code the violation took place and usually trace information to track down the root cause.
Dynamic testing applies to running applications. These tools detect problems in running applications and perform testing by adding small bits of code called instrumentation to help determine code coverage and answer the question, have I done enough testing?
Errors are reported as the application runs and usually provide context information so developers can find and fix the detected vulnerabilities.
The main differences between static and dynamic security testing tools include the following.
Dynamic tools like DAST tools can only be applied to running applications and therefore come later in development. However, with modern CI/CD pipelines, running applications are available sooner and more often than before, making DAST tools more useful.
Dynamic tools, on the other hand, can incorporate test frameworks to automate test case generation, stubbing, mocking, take advantage of instrumentation, and use special runtime libraries to detect vulnerabilities while the application is running. They also include capabilities to capture and report on these findings. Trace information is usually included, which makes for quick remediation. Since these errors are actually occurring in a running application, there are usually no false positives.
DAST tools, on the other hand, detect vulnerabilities in executing code. There’s a high degree of confidence in these findings. In addition, runtime conditions, such as complicated multithreaded behavior, introduce new types of errors and vulnerabilities that SAST tools miss.
SAST tools have to trade off false positives with potentially missing real vulnerabilities, known as false negatives, in order to provide the best ROI for securing source code. False positives are always possible with SAST tool analysis, but the payoff is early detection of vulnerabilities that might be missed in later testing.
Both SAST and DAST tools can miss real errors. However, best practice is to use both tools together to reduce errors.
SAST tools do not require a running application and therefore can be used early in the development lifecycle where remediation costs are low. At its most basic level, SAST works by analyzing source code and checking it against a set of rules. Usually associated with identifying vulnerabilities, SAST tools provide early alerts to developers regarding poor coding patterns that lead to exploits, violations of secure coding policies, or a lack of conformance with engineering standards that will lead to unstable or unreliable functionality.
There are two primary types of analysis used for identifying security issues.
In flow analysis, the tools analyze source code to understand the underlying control flow and data flow of the code.
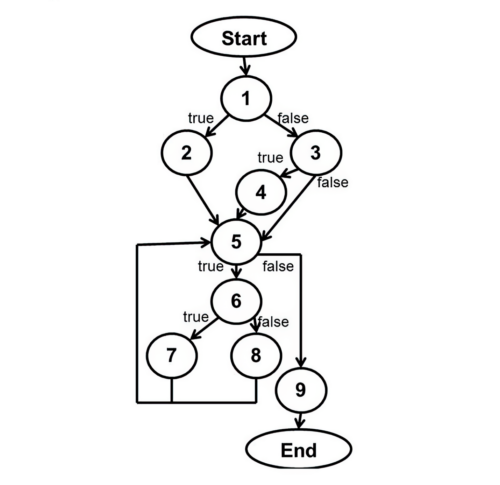
Static Analysis Security Testing – Flow Analysis
The result is an intermediate representation, or model, of the application. The tools run rules—or checkers—against that model to identify coding errors that result in security vulnerabilities. For example, in a C or C++ application, a rule may identify string copies, then traverse the model to determine if it is ever possible for the source buffer to be larger than the destination buffer. If it is, a buffer overflow vulnerability could result.
Avoiding certain constructs in code that’s safety-critical is the basis behind modern software engineering standards like AUTOSAR C++14, MISRA C 2023, and Joint Strike Fighter (JSF). These standards prevent the possibility of misinterpreting, misunderstanding, or incorrectly implementing unreliable code.
Pattern analysis helps developers use a safer subset of the development language given the context of safety or security, prohibiting the use of code constructs that allow vulnerabilities to occur in the first place. Some rules can identify errors by checking syntax, like a spell checker in a word processor. Some modern tools can detect subtle patterns associated with poor coding construction.
Each testing methodology has strengths. Many organizations overly focus on DAST and penetration testing. But there are several advantages to using SAST over other testing techniques.
The amount of code that’s tested is a critical metric for software security. Vulnerabilities can be present in any section of the codebase, and untested portions can leave an application exposed to attacks.
SAST tools, particularly those using pattern analysis rules, can provide much higher code coverage than dynamic techniques or manual processes. They have access to the application source code and application inputs, including hidden ones that are not exposed in the user interface.
SAST tools promote efficient remediation of vulnerabilities. Static analysis security testing easily identifies the precise line of code that introduces the error. Integrations with developers’ IDE can accelerate remediating errors found by SAST tools.
Developers receive immediate feedback on their code when they use SAST tools from the IDE. The data reinforces and educates them on secure coding practices.
Developers use static analysis early in the development lifecycle, including on single files directly from their IDE. Finding errors early in the SDLC greatly reduces the cost of remediation. It prevents bugs in the first place, so developers don’t have to find and fix them later.
SAST is a comprehensive testing methodology that does require some initial effort and motivation to adopt it successfully.
While teams can use SAST tools early in the SDLC, some organizations elect to delay analysis until the testing phase. Even though analyzing a more complete application allows for inter-procedural data flow analysis, "shifting left" with SAST and analyzing code directly from the IDE can identify vulnerabilities such as input validation errors. It also enables developers to make simple corrections before submitting code for builds. This helps avoid late-cycle changes for security.
SAST analysis is misunderstood. Many teams think it’s time-consuming because of its deep analysis of the entire project source code. This can lead organizations to believe SAST is incompatible with rapid development methodologies, which is unfounded. Nearly instantaneous results from static analysis security testing are available within the developer’s IDE, providing immediate feedback, and ensuring avoidance of vulnerabilities. Modern SAST tools perform incremental analysis to view results only from the code that changed between two different builds.
Traditional static analysis security testing tools often include many "informational" results and low-severity issues around proper coding standards. Modern tools, like those that Parasoft offers, allow users to select which rules/checkers to use and filter results by the severity of the error, hiding those that do not warrant investigation.
Many security standards from OWASP, CWE, CERT, and the like have risk models that help identify the most important vulnerabilities. Your SAST tool should use this information to help you focus on what matters most. Users can filter findings more based on other contextual information like metadata on the project, the age of the code, and the developer or team responsible for the code. Tools like Parasoft provide use of this information with artificial intelligence (AI) and machine learning (ML) to help further determine the most critical issues.
Successful deployments are often developer-focused. They provide the tools and guidance developers need to build security into the software. This is important in Agile and DevOps/DevSecOps environments, where rapid feedback is critical to maintaining velocity. IDE integrations allow security testing directly from the developer’s work environment—at the file level, project level, or simply to evaluate the code that changed.
When analyzing software for security issues, one size does not fit all organizations. It’s critical that the rules/checkers are addressing the specific issues critical to that specific application. Organizations just starting testing for security may wish to limit rules to the most common security issues like cross-site scripting and SQL injection. Other organizations have specific security requirements based on regulations like PCI DSS. Look for solutions that allow controlled rule/checker configuration that fits your specific needs, not a generic configuration.
In the case of software security tools, the whole is better than the sum of the parts. This is true of application security testing because the various tools have strengths in different areas and weaknesses that are mitigated by the combination.
The combination of SAST and DAST is a natural fit due to the fundamental difference in the technology used in static tools versus dynamic tools. Here are some of the benefits of integrating both into your security testing.
Integrating tools, in general, can be challenging. Tools from different vendors may not play well together and the reports from each tool may conflict and be in varying formats. This leads to the following challenges.
There’s excellent ROI for integrating your application security toolbox, so this list shouldn’t discourage the effort. Here are some best practices to help ease the integration:
In addition to SAST and DAST, there are other types of application security testing.
It’s important to note that these are application security testing techniques that fit within an ecosystem of security techniques. For example, teams commonly use application security orchestration tools to organize, analyze, and report on the information from all of these techniques.
Artificial intelligence (AI) and machine learning (ML) technologies enhance Parasoft’s static analysis solutions to identify hotspots and intersections between all of the found violations. This enables teams to focus efforts on the part of the codebase that is the root cause for many other issues. What’s more, ML monitors and learns from the behavior of your development teams to differentiate between what’s important and what’s not.
Training your AI model based on the historic behavior of the development team provides a multi-dimensional analysis of the findings, while ML clusters data to identify correlated, related, or similar violations.
Combining the two technologies is even better. The combination learns which false-positive results to ignore and which true positives to highlight. It shrinks a mountain of information down to a few, highly valuable diamonds.
For example, static analysis can reveal thousands of violations in a typical codebase. Even though you might be able to identify hundreds of defects to address, you won’t be able to fix everything in the amount of time available. With AI and ML finding violation hotspots, you can fix multiple defects at the same time by identifying the single piece of code that’s causing all of them.
Build security into your application. It’s much more effective and efficient than trying to secure an application by bolting security on top of a finished application at the end of the SDLC. Just as you cannot test quality into an application, the same is true for security. SAST is the key to early detection and prevents security vulnerabilities by writing secure code from the start.
SAST tools enable organizations to embrace software security from the early stages of development onward and provide their software engineers with the tools and guidance they need to build secure software.
"MISRA", "MISRA C" and the triangle logo are registered trademarks of The MISRA Consortium Limited. ©The MISRA Consortium Limited, 2021. All rights reserved.


